
| 研究概要 | |
|
近年、拘束が多様に切り替わる可変拘束系に対する制御が研究されており、
そのような対象の一つにロボットによる鉄棒技能生成がある。具体的には、
アクロバットロボットによる大車輪運動、そして空中へ
飛び出して回転し着地するといった連続技を実現するものである。
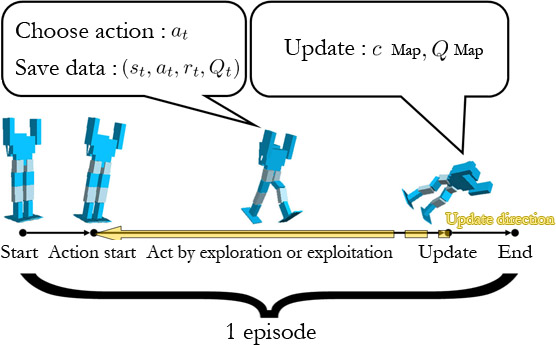
下記左の動画は、飛び出しからの空中回転を実機で検証したものである。 本研究では接地状態を切替える転倒回避を実機で実現することを目指す。 アクロバットロボットに対し、接地状態の切替えを考慮した動力学モデルに 基づくコントローラを設計するのは困難である。この観点から、行動選択の 指針となる関数を試行錯誤の繰り返しによりシステマティックに求めることが できる Q-Learning を用いる。 本研究では、Q関数をガウス関数の足し合わせにより近似する手法を用いる。 しかしこの方法では学習過程でQマップを更新する際の計算量が膨大であるため、 サンプリング時間内に計算を終了することが困難であり、実機に適用できない。 従って、学習行動時は行動選択とデータの保存のみを行い 更新は行動選択後にまとめて行うことで計算時間を短縮するオフラインアルゴリズムを用いる。 この際、Qマップの収束速度を向上させるため更新作業は逆時間方向に行う。 本アルゴリズムは実機でのサンプリング時間内に計算可能であることが 確認され、また数値シミュレーションにより、Qマップの収束が確認された。 下記右動画はその時の様子を示している。 さらにこのアルゴリズムを実機に適用し、学習過程の途中で 一部の初期値に対しては転倒回避に成功する行動パターンが得られ、実機に おける学習が可能であることを確認した。 | |
| 公開動画 | |
| 動画1,動画2 |
